Teaching Large Language Models to Self-Debug: A New Frontier in AI-Powered Coding World.
From code generation to natural language understanding, large language models, or LLMs, have transformed many fields. Even while these models can produce intricate code fragments, it is still difficult to guarantee their accuracy in a single try.
To solve this problem, a novel method called SELF-BUGGING was created, which enables LLMs to independently debug their own code predictions. This blog explores the ideas, methods, and applications of SELF DEBUGGING to show its revolutionary potential.
Let’s examine the definition of self-debugging.
SELF-DEBUGGING educates LLMs to recognize and fix mistakes in their code predictions through backpropagations without human assistance. This technique enables models to perform certain complex tasks, drawing inspiration from the conventional idea of Rubber Duck Debugging, in which programmers walk a fictional listener through their code line by line to identify mistakes from the base code.
Execute Code: To see the outcomes of execution, first run the code they generated.
Explain Code: Describe their code and its behaviour in clear English.
Iteratively Refine: Make improvements to their forecasts iteratively by using execution and explanation feedback.
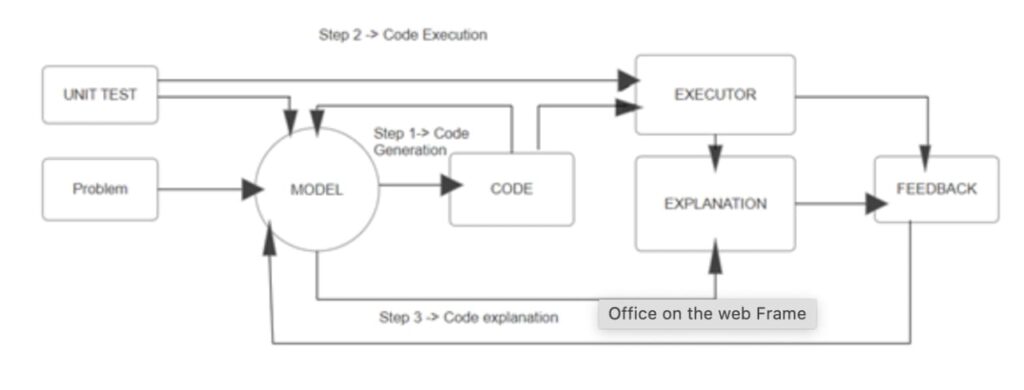
This procedure greatly increases the usefulness of LLMs for developers by enabling them to go beyond simply producing code to actively participating in debugging.
Why SELF DEBUGGING Matters?
It is rare for even human programmers to write perfect code on their first try. Likewise, it frequently takes several rounds for LLMs to generate accurate solutions. Conventional methods for increasing accuracy include creating numerous samples and reranking them, which uses a lot of processing power. These restrictions are addressed by SELF DEBUGGING by
- Reducing Sample Dependency: Achieving high accuracy with fewer generated samples.
- Improving Code Understanding: Encouraging models to comprehend their code beyond surface-level patterns.
- Boosting Performance: Enhancing accuracy across diverse coding tasks, from text-to-SQL generation to language translation.
Explaining the Self-Debugging Framework
The self-debugging framework transforms the working of Large Language Models handle code generation by teaching them to debug code without any Human help.
This framework relies on iterative refinement for debugging the code going through it again and again, where the models generate, explains, tests and improves its code until it is error free.
How it works
The self-debugging process involves four main steps:
- Code generation -> The model first creates a mock solution based on the input problem.
- Code Explanation -> It then explains its thought process, describing the logics working behind the code. This step ensures that the model understands the problem on a deeper level.
- Iterative Refinement -> The model revises its code based on feedback and continues testing until all errors are resolved through backpropagation.
Example
Imagine converting a Python function to calculate factorials into JavaScript. The model generates initial translations, explains how it works, tests it with inputs like 0 and 5 that identify an error in handling the edge cases and iteratively refines the code until it works perfectly.
How Does SELF DEBUGGING Work?
The three main steps of the SELF DEBUGGING framework are:- Code Generation: Using the problem as a guide, the model generates basic code.
- Code Explanation: By mimicking a human-like review process, the model uses natural language to explain the logic and operation of the code.
- Integration of Feedback: Feedback is produced in response to logical inconsistencies in the explanation or execution outcomes. The model updates and enhances its code based on these comments.
- Analyzes the Python Function -> Overview Python function is designed to check “if a number is prime”, breaking down it into logic step by step.
- Translate the Code -> Generates an initial JavaScript Equivalent of the Python functional.
- Tests the Translation -> Executes the JavaScript code on a range to ensure it behaves as expected.
- Refines Based on feedback -> Identifies errors, such as incorrectly handling edge cases (e.g. Negative numbers 0 and 1) and iteratively updates the JavaScript code until it produces correct results for all test cases.
Applications of SELF DEBUGGING
Self-debugging has proven effective for a variety of coding jobs, such as: Text-to-SQL Generation: Producing precise SQL queries from descriptions in natural language, even in the absence of unit testing. Code Translation: Converting code across languages, such as C++ to Python, while maintaining function equivalency is known as code translation. Text-to-Python Generation: Using partial test cases to refine Python code written in response to natural language cues.C++ Programme
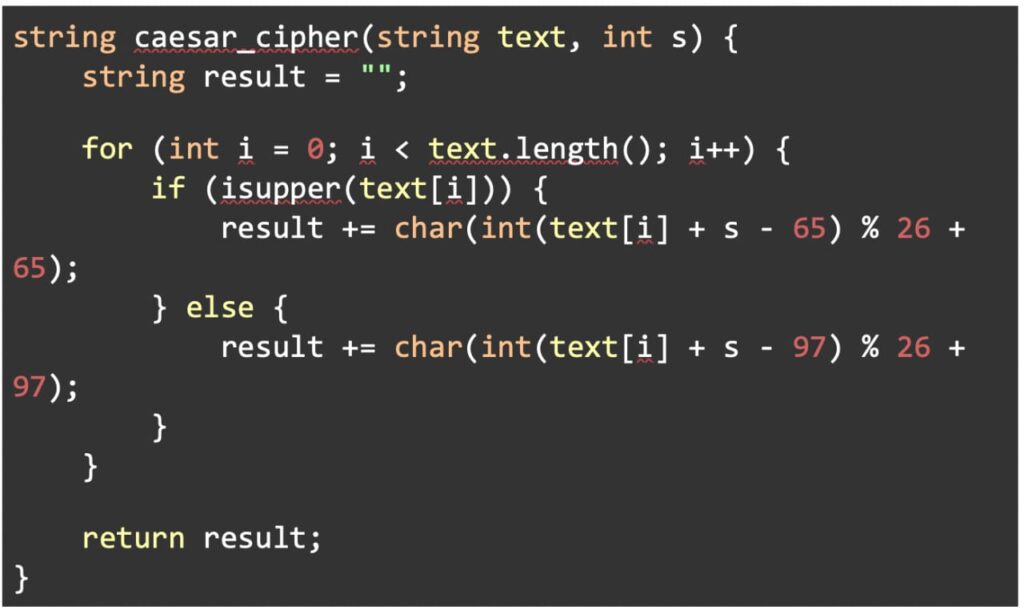
Python Programme

In these scenarios, SLEF DEBUGGING outperformed traditional methods by improving prediction accuracy by up to 12%, particularly for a complex problem.
KEY BENEFITS
- State of the art performances: SELF DEBUGGING has set new benchmarks across multiple coding datasets, such as Spider(text-to-SQL), TransCoder (code translation), and MBPS (Python generation).
- Enhanced Sample Efficiency: By leveraging iterative debugging, the method archives comparable or superior results with fewer candidate solutions.
- Independence from External Feedback: SELF DEBUGGING operates efficiently even in the absence of unit test or human annotations, relying solely on the model’s reasoning capabilities.
Challenges and Future Directions
Even though self-debugging has shown a lot of potential, there are still several obstacles to overcome:
- Error Detection Accuracy: Enhancing the model’s capacity to recognize minute logical and semantic mistakes is known as error detection accuracy.
- Feedback Richness: Improving the informativeness of model-generated input is known as feedback richness.
- Scalability: Adapting the approach to manage more complicated and sizable projects.
Further research may focus on improving code explanation techniques and integrating additional debugging signals such as semantic analysis or error prediction models.
Conclusion
So, we concluded part, SELF DEBUGGING is a major advancement in LLMs’ ability to do code-related activities. This approach not only improves performance but also brings LLM behaviour closer to human-like problem-solving by educating models to iteratively improve their outputs. SELF DEBUGGING emphasizes the significance of enabling machines to learn, adapt, and improve on their own as AI develops.
SELF-DEBUGGING provides a glimpse into the future of AI-Driven development, where computers are not only tools but participants in this cutting-edge environment, regardless of whether you are a developer, researcher, or IT enthusiast.