
What is retrieval augmented generation (RAG)?
We can say that in retrieval-augmented generation (RAG), we are using two different kinds of computer tricks to help LLM respond and understand the data in a better way. One of these two tricks is that computers can find information from libraries, articles, blogs, and websites. And in the other trick, it generates itself using this knowledge. Then we mix these two tricks and make a computer that can generate a better answer when someone asks a question.
How does retrieval augmented generation (RAG) work?
When someone asks a question, the computer first tries to find out related information. Then it sends that useful information and a question to the computer program that knows about language. This computer program uses the information from the document to generate a smart answer in such a way that it looks like someone is giving an answer.
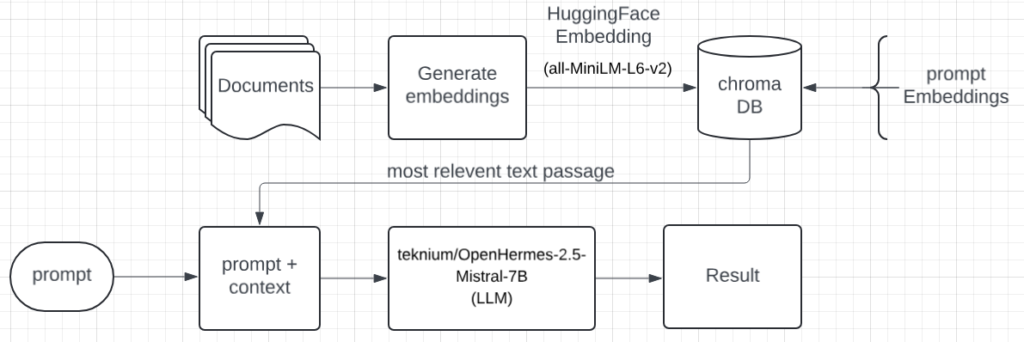
Block Diagram

Import necessary libraries
Set up directories for output files and embeddings
Read training and testing data
Preprocess the data
Create documents and metadata from training data
Embed the documents
Save the embeddings
Load embeddings into ChromaDB
Initialize a retriever
Set up the language model and tokenizer
Define the QA pipeline
Initialize a callback handler
Retrieve answers for the test data
Langchain
What is Langchain?
Langchain is a tool that helps RAG work in a smarter way. Langchain is designed for computers to handle language data more easily. It organizes all the data systemically, which can help computers find sentences and words very quickly. Because of this way of storing data, when the computer is looking for information to answer the input question, using Langchain will be easier, faster, and much smarter.
How does Langchain work?
Langchanin saves the language data into a structured format that allows us to find out the data quickly and efficiently during the process. It uses advanced techniques for information retrieval to index and store language data in a way that allows for fast and accurate access.
Question and Answering with RAG
Importing Libraries

Setting Up Directories

Data Preprocessing

Initializing Documents and Metadata

Embedding Documents

Setting Up Chroma DB

Initializing Retriever

Loading Language Model

Retrieving Answers and Generating Output

CONCLUSION
In conclusion, retrieval-augmented generation (RAG) combined with Langchain provides a very fast and accurate approach to enhancing language models and even up-to-date information. To generate human-like answers, RAG integrates with document retrievers and language generation to answer the input question. Langchain further enhances this by organizing the data in a very well-structured format for easy and fast retrieval, which helps to give fast, accurate, and effective responses. Together, RAG and Langchain enhance the communication between machines and humans in a more intelligent and effective way, and they use both existing knowledge and the latest information.


