

Introduction
Large Language Models (LLMs) have transformed how we build AI. Models like GPT-4, LLaMA, and Claude can write code, answer questions, and even generate images or audio. But training these models requires enormous amounts of labeled data, powerful hardware, and energy.
This creates big problems:
- High costs (millions of dollars).
- Poor accessibility for small teams or researchers.
But what if we could make language models smarter without training them from scratch every time?
That’s where “MODEL CONNECTOMES” come in.
This blog breaks down how it works, why it matters, and how it could shape the future of AI.
Why Do We Need Model Connectomes?
Today, most AI models start learning with random weights and no structure. Each new model is trained from scratch, even though similar tasks have already been learned by older models. This is wasteful in terms of:
- Repeated learning
- Inefficient use of knowledge
- High compute and data cost
Training large models requires:
- Billions of tokens
- Powerful GPUs or TPUs
- Massive energy consumption
Yet, much of the learning process involves rediscovering the same patterns (e.g., grammar, reasoning, logic). There's no reuse of learned structure.
Model Connectomes aim to solve this problem by:
- Finding which neural connections (weights) are actually important after training.
- Pruning and binarizing them into a reusable structure.
- Passing this sparse structure to future models.
This way, new models don’t start from zero. Instead, they begin with a pre-learned structure, which makes them:
- Learn faster
- Use less data
- Require fewer resources
What is a Model Connectome?
A Model Connectome is a sparse, binary structure of a trained model. It keeps only the most important connections (weights), and removes the rest.
- Sparse means most connections are removed.
- Binary means the remaining ones are set to simple values: +1 or -1.
- This connectome acts as a wiring diagram — like a brain blueprint — and is reused in other models.
- New models can then use this wiring to learn new tasks with much less training data.
How It Works: Two-Stage Learning Process
Model Connectomes split learning into two loops:
1. Outer Loop – Evolution Stage:
This is where we discover which connections in a model are important. Steps:
- Train a normal language model on a big dataset (e.g., TinyStories with 4 billion tokens).
- After training, prune the model by removing the lowest-weight connections (these contribute least to performance).
- Keep only the strongest connections.
- Convert those weights to +1 or -1 (called binarization).
- Save this structure as a connectome—a sparse binary map of useful paths.
2. Inner Loop – Learning Stage
Now we use this connectome to train a new model on a small dataset (e.g. just 100 million tokens).
Steps:
- Initialize a new model with random weights.
- Apply the saved connectome mask: only the allowed connections are used.
- Train on the small dataset.
- The model learns faster because it already has a structure that worked before.
Flowcharts:
Below is the basic explanation of the flowcharts:
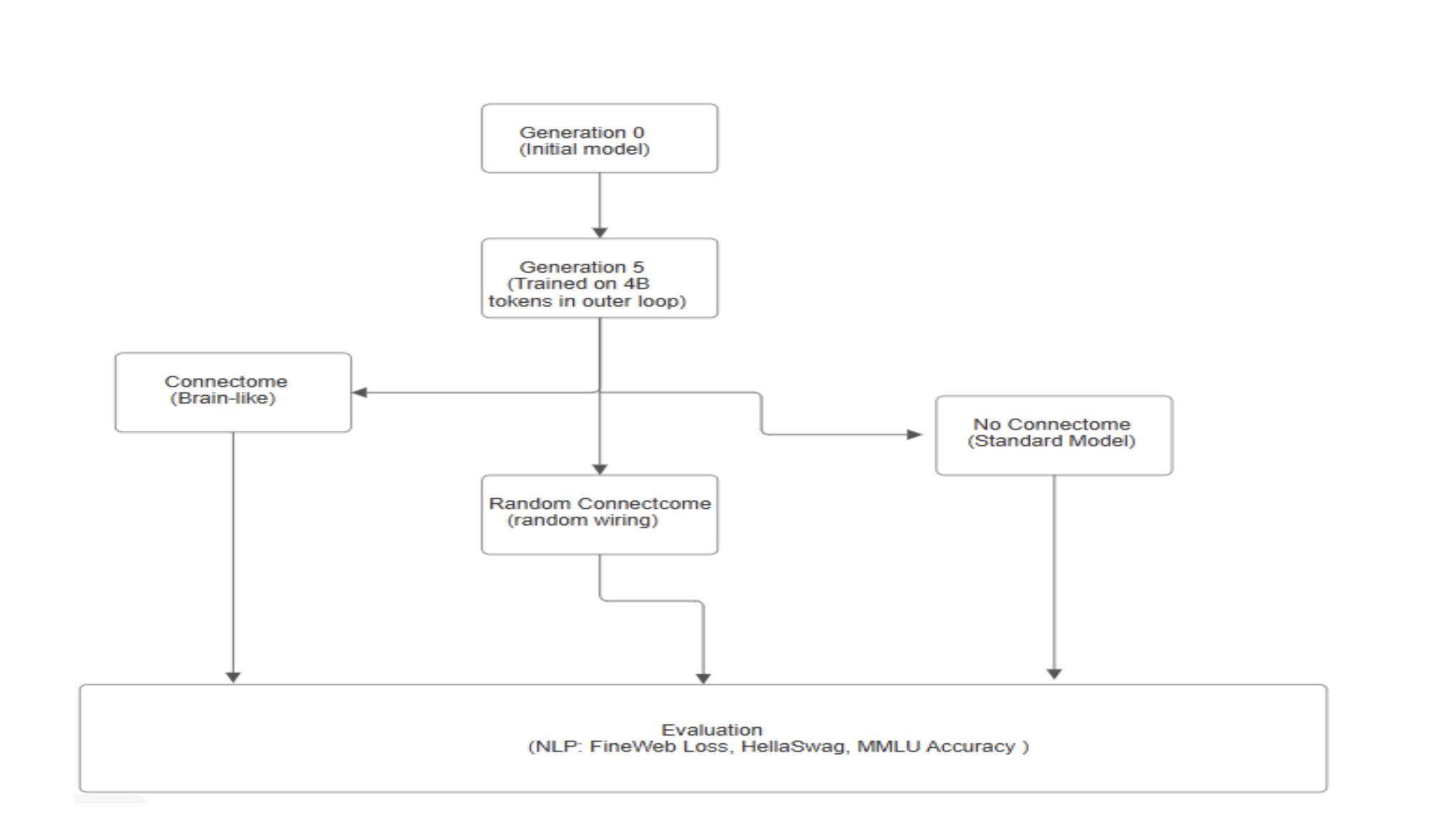
1. Generation 0 (Initial Model): This is the initial model that is simple and not trained much.
2. Generation 5 ( Intermediate Trained Model): This model is trained further on 4 billion tokens using a standard training loop. This forms the basis for structural experimentation
3. Architectural Variants: After Generation 5, the architecture splits into three branches, each representing a different wiring hypothesis:
- No Connectome (Standard Model): This branch retains the conventional transformer architecture without any structural modifications.
- Random Connectome (Random Wiring): Here, the internal connections of the model are randomly rewired, testing the effects of non-deterministic and non-biological structuring.
- Connectome (Brain-like): This variant uses inspired wiring from biological brains, possibly mimicking structural motifs observed in the human connectome.
4. Evaluation Phase: All three architectural variants are evaluated on key NLP benchmarks:
- FineWeb Loss: A measure of language modeling performance.
- HellaSwag: For commonsense reasoning.
- MMLU Accuracy: A test for general knowledge and reasoning.
Real-World Use Cases
- Education AI: Build smart tutoring systems that learn quickly and give personalized help to limited train students, even wing data.
- Low-resource regions: Create models that work well in rural or underdeveloped areas, where internet, data, or computing power is limited.
- On-device AI: Use connectomes to train smaller, faster models that can run directly on phones, tablets, or smart home devices — no need for the cloud.
- Scientific Research: Help researchers build AI systems that learn like the brain, useful for studying memory, learning, and decision-making in a more natural way.
Future Improvements:
- Smarter pruning: Instead of just removing small weights, use smarter methods to find which connections really matter.
- Use in bigger tasks: Try connectomes in harder problems like code writing, deep reasoning, or smart conversations.
- Separate connectomes for each skill: Like how our brain has different parts (for language, memory, etc.), we could have special connectomes for different tasks.
- Connectomes that adapt over time: Let the connectome learn and update as users interact with the model — just like lifelong learning in humans.
- Open sharing: Share connectomes online, so others can reuse and improve them - just like open-source model weights.
Benefits :
- Trains faster - due to built-in structure.
- Needs less data—just 100M tokens is enough.
- More environmentally friendly—less power needed.
- Better generalization—less overfitting.
- Reusable—connectomes can be passed to future models.
Final Thoughts:
Model Connectomes are a new idea inspired by the human brain. Instead of training every new AI model from the beginning, we can reuse useful parts learned by earlier models. This makes AI smarter and more efficient.
Even though it’s still being developed, this method already shows big benefits:
- Faster training with less data
- Cheaper and easier to run
- Smaller models that can work on personal devices
In the future, AI may not need huge datasets or powerful machines to learn. Thanks to connectomes, we are moving closer to building AI that learns faster, uses less, and gets better overtime — just like how humans do.


