Understanding LoRA (Low-rank Adaption) for fine tuning language models –
Within the past few years language models (LMs) have gone through incredible progress and new inventions. Various models like BERT, GPT have shown impressive results over the various applications like text generation and sentiment analysis. Although developing these big models for specific purposes remains challenging and sometimes overpriced too. This is the area where LoRA (Low-rank Adaption) takes into action. This technique drastically reduces the amount of computation power and memory required in order to optimize large language models.
What is LoRA (Low-rank Adaption) –
A method called LoRA (Low-rank Adaption) has been invented to deal with the efficiency concern with fine tuning of large models. During the fine-tuning a pre-trained model, LoRA introduced a couple of incremental low-ranked matrices which are fine-tuned whereas the original model’s parameters are unchanged and remains unmodified comparing to alternative all the model’s performances simultaneously decrease the total number of parameters that can be trained enabling fine tuning without compromising the model’s accuracy and performance.
How does LoRA works –
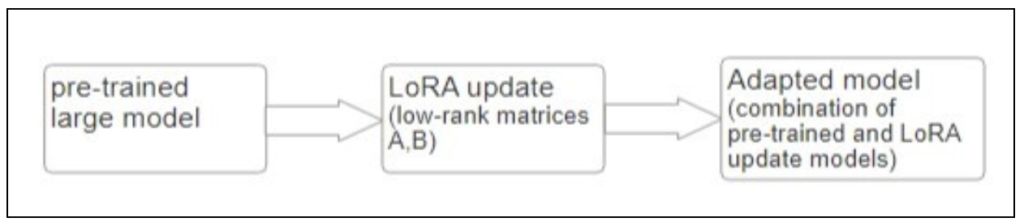
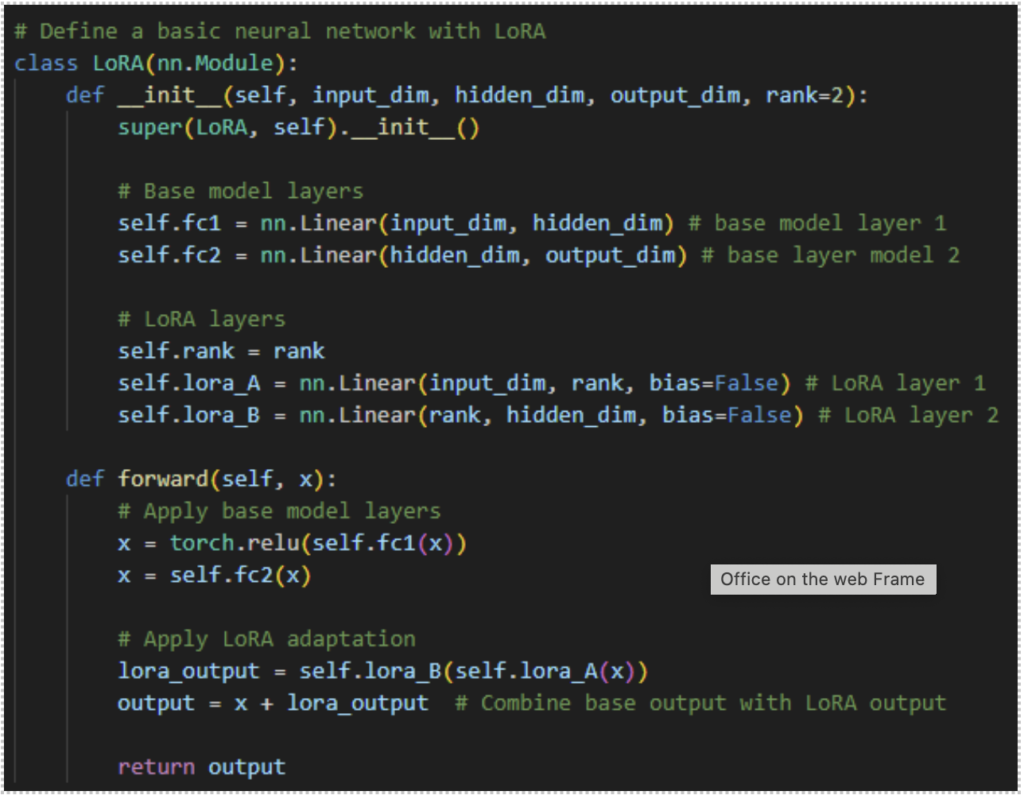
LoRA introduces low-rank matrices during fine-tuning updating only the particular layers of pre-trained models. The initially pre-trained model parameters remain frozen while these matrices are altered. The basic concept is to separate a model’s weight matrix WWW into two smaller matrices AAA and BBB.
W=W0+ΔWW = W_0 + \Delta WW=W0+ΔW
here W0W_0W0 represents the frozen pre-trained parameters, and ΔW\Delta WΔW is the update matrix that is decomposed into low-rank matrices AAA and BBB
ΔW=A×B\Delta W = A \times BΔW=A×B
Both AAA and BBB are learned during the fine-tuning process, but they contain far fewer parameters than the full matrix WWW. The decomposition ensures that the model still performs effectively but the number of parameters that need updating significantly reduced.
Flowchart –
Code snippet –
1. Import libraries

2.Neural Network of LoRA
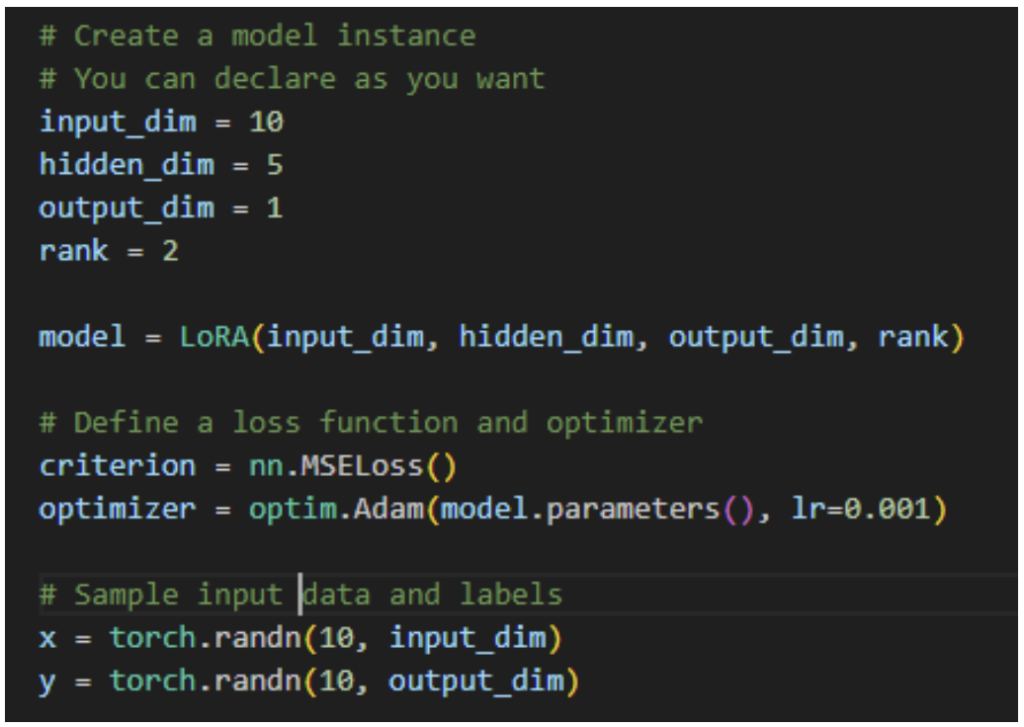
3.Create model instance.
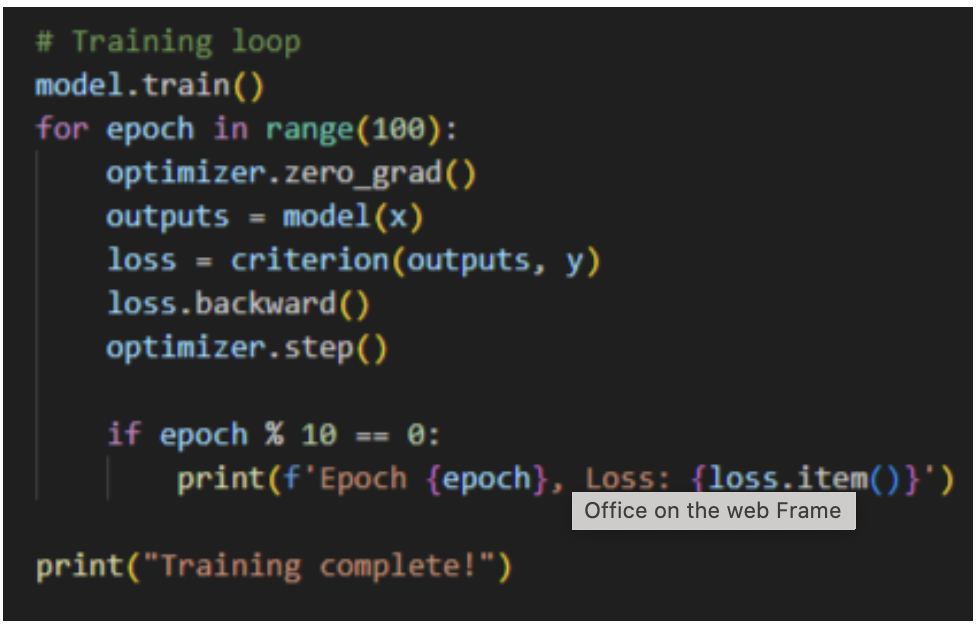
4.Training.
Why use LoRA ?
A substantial amount of processing capacity to fine-tune the entire model, especially those with billions of parameters. To accomplish this, LoRA (Low-rank Adaption) includes a few trainable parameters, that enhances the effectiveness of the fine-tuning approach in the following ways:
- Memory Efficiency –
During fine-tuning, only a tiny portion of the model parameters are modified which reduces the total amount of memory used.
- More rapid training –
Fine-tuning needs less time because there are significantly fewer parameters to tune.
- Adaptability –
LoRA (Low-ranked Adaption) is an excellent business with limited resources because it can scale extremely large models while maintaining low utilization of resources.
Benifits of LoRA –
- Reduced computational costs –
Contrary to conventional approaches, fine-tuning through LoRA is more computationally efficient since simply a handful of parameters are adjusted.
- Lower Memory Requirements –
LoRA drastically reduces the memory required for fine-tuning, enabling big models to be fine-tuning on hardware designed for customers.
- Flexibility –
LoRA may be used for an extensive variety of activities across different language models, covering text classification, generation & translation.
- Compatible performance –
LoRA is an attractive alternative for many use cases because, despite its low price, it often produces performance comparable to that of finished fine-tuning techniques.
Use cases of LoRA –
- Resources-Constrained Environments – LoRA enables it to feasible to fine-tune large models without having to pay for expensive hardware, like multiple GPU’s in circumstances where organizations have limited computational resources.
- Faster development for specific Domains – LoRA allows researchers and data scientists to experiment rapidly with fine-tuning various models.
- Model adaptation for specific domains – LoRA can be used to improve general-purpose models for duties such legal document classification, medical text analysis, or customer service chatbots, in applications which are industry-specific.
Conclusion –
LoRA offers an effective, scalable, and affordable way for modifying large-scale models, making it an important milestone in the field of language model fine-tuning. LoRA reduces the number of trainable parameters through the use of low-rank matrices, allowing organizations with limited computational resources to utilize the benefits of the possibilities of big language models for specific applications.
Techniques like LoRA will be increasingly important for democratizing access to complex NLP systems as models keep growing in size.