Language Modeling with Explicit Memory
Large language models’ (LLMs’) growing size and complexity lead to high training and inference expenses. These expenses result from the need to encode enormous volumes of information into model parameters, which are costly to compute and resource-intensive. As the demand for more powerful models grows, the challenge of managing these costs becomes more pronounced.
What is Implicit and Explicit Memory
The type of knowledge that is incorporated into model parameters during training is known as implicit memory. It describes the broad knowledge that the model picks up through experiences, associations, and patterns without having to actively remember information.
Externalized knowledge that may be retrieved when needed is known as explicit memory. Explicit memory is stored freely and can be accessed or modified independently, in contrast to implicit memory, which is incorporated into the model’s parameters. For tasks requiring more specific or uncommon information, it enables the model to retrieve particular facts from a memory bank.
How does it work
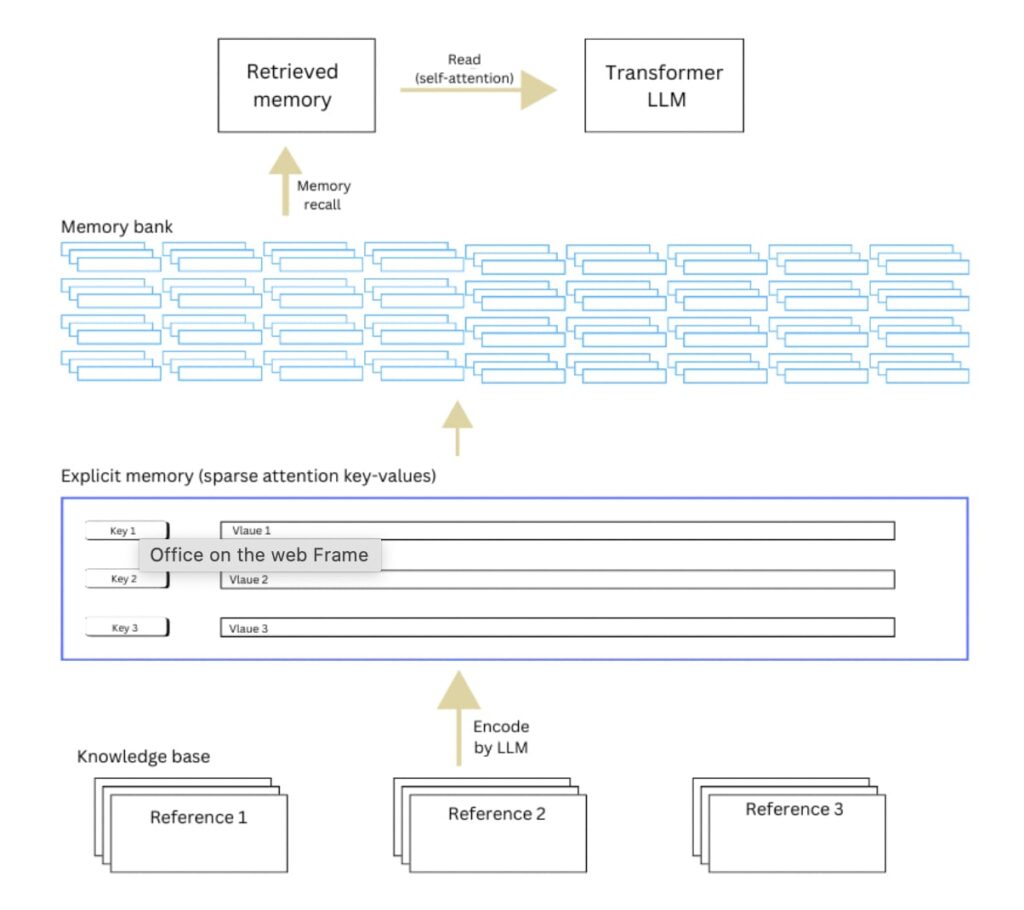
Converting Raw Text into Explicit Memory-
The procedure starts with an extensive knowledge base, which consists of a compilation of raw text information like books, articles, or organized datasets.
The original text is examined and divided into key-value pairs to create a structured and accessible format. This transformation is typically carried out with a trained language model that detects the most pertinent sections of the text to retain.
The text undergoes additional processing into sparse attention key-values—a condensed format designed for seamless integration with the model. These key-values are kept in a format that reduces storage size while maintaining significance.
Storing Explicit Memory in the Memory Bank
All the processed key-value pairs are stored in a memory bank, functioning as an external storage unit (such as SSD, RAM, or a database). This memory bank is distinct from the model’s parameters and acts as a scalable knowledge repository.
The memory bank is organized for quick access, frequently employing similarity search algorithms such as cosine similarity or various vector search techniques.
The memory bank can be independently updated without needing to retrain the whole model.
Retrieval During Inference
The model tokenizes and encodes the query. The model then looks through the memory bank for the key-value pairs that are most pertinent.
The extracted key-value pairs are incorporated into the model as explicit memory. The model’s self-attention mechanism receives the sparse attention representations of the retrieved memory.
The explicit memory (retrieved key-values) is integrated with the model’s implicit memory (information stored in its parameters).
This integration allows the model to think and produce a reply based on its internal knowledge as well as its external explicit memory.
Implementation by Code
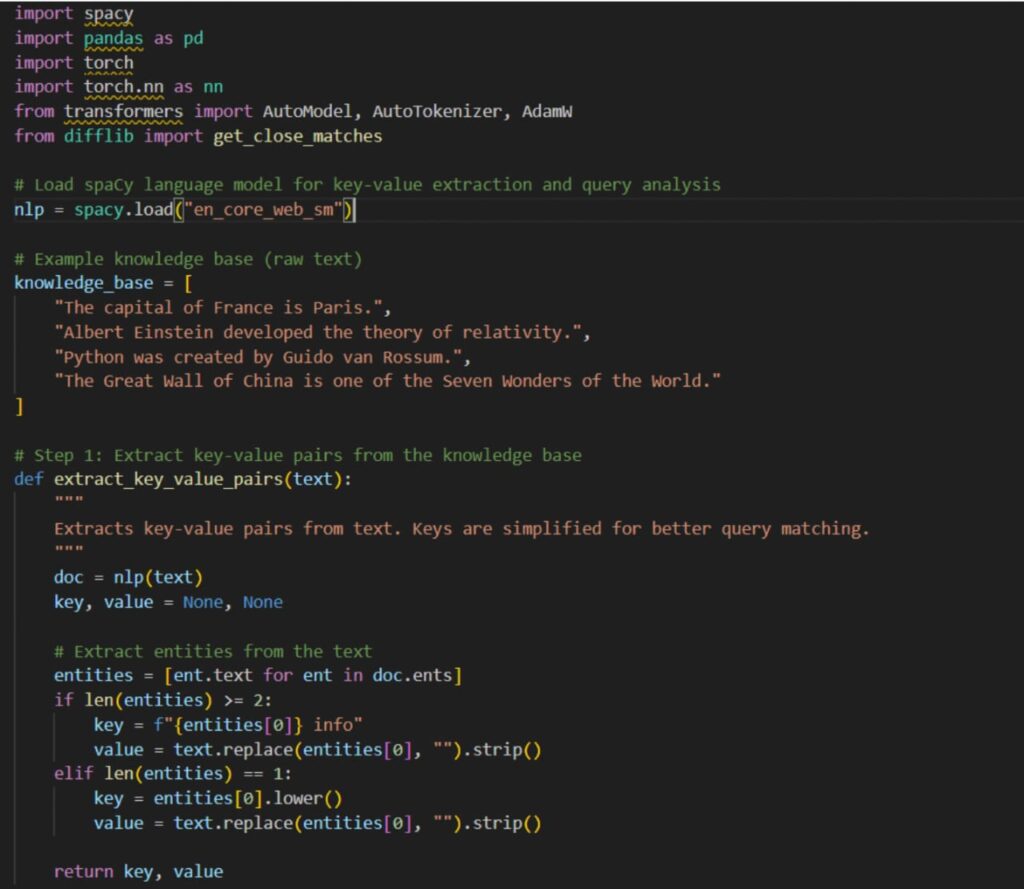
- Import all the necessary libraries and exact key-value form the data or knowledge base
2. Storing the key-value pair in memory bank

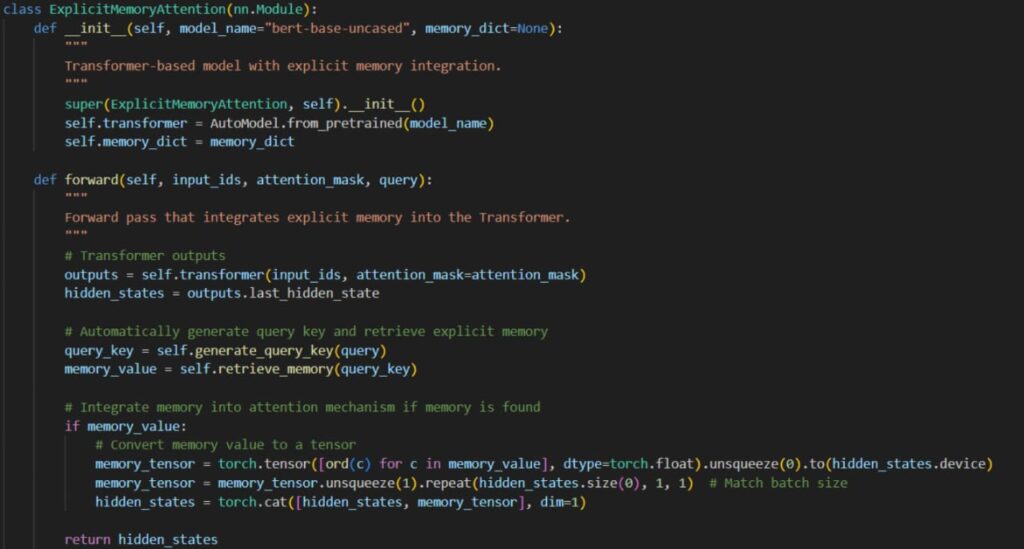
3. Define the model and integrate memory bank with it
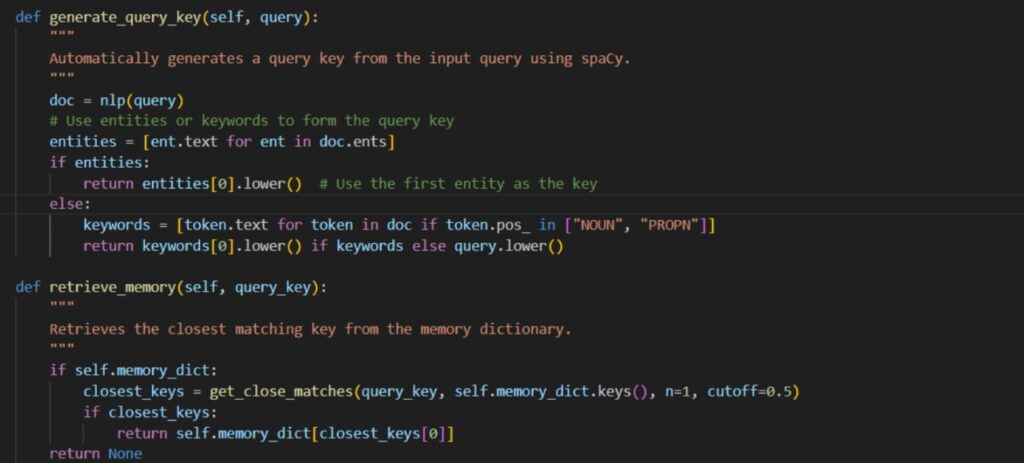
4. Define a function to generate key from query and find closest matching key
5. Create data loader and initialize it
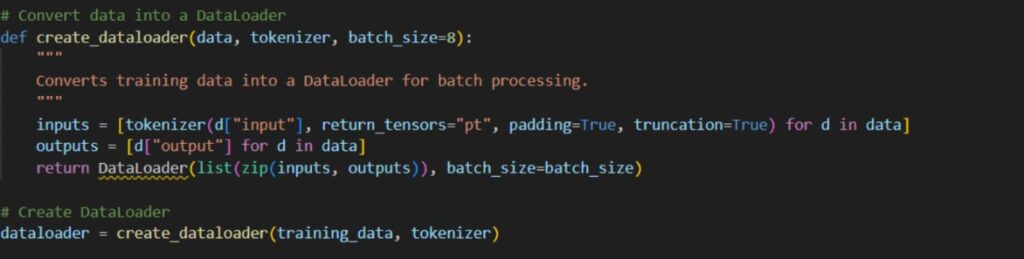
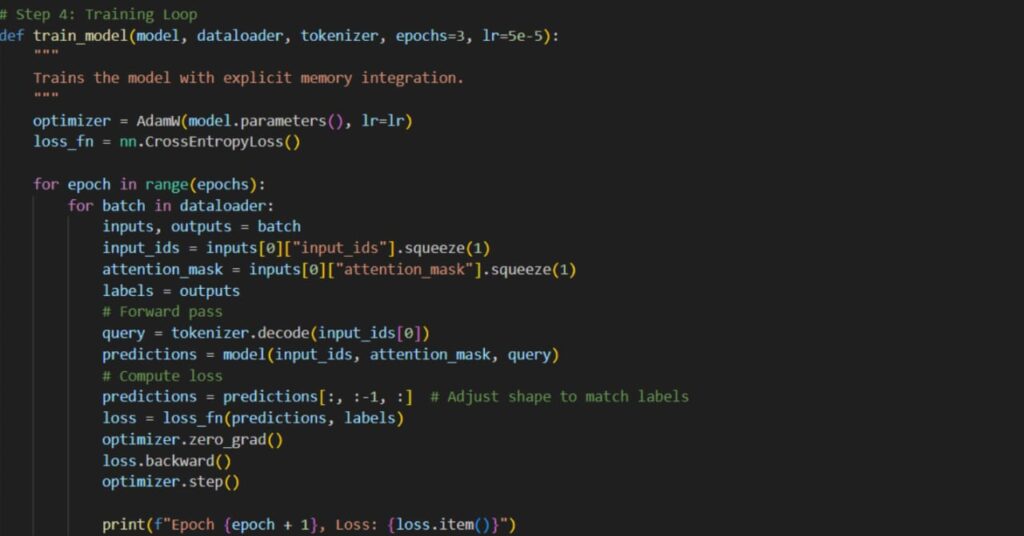
6. Training the model
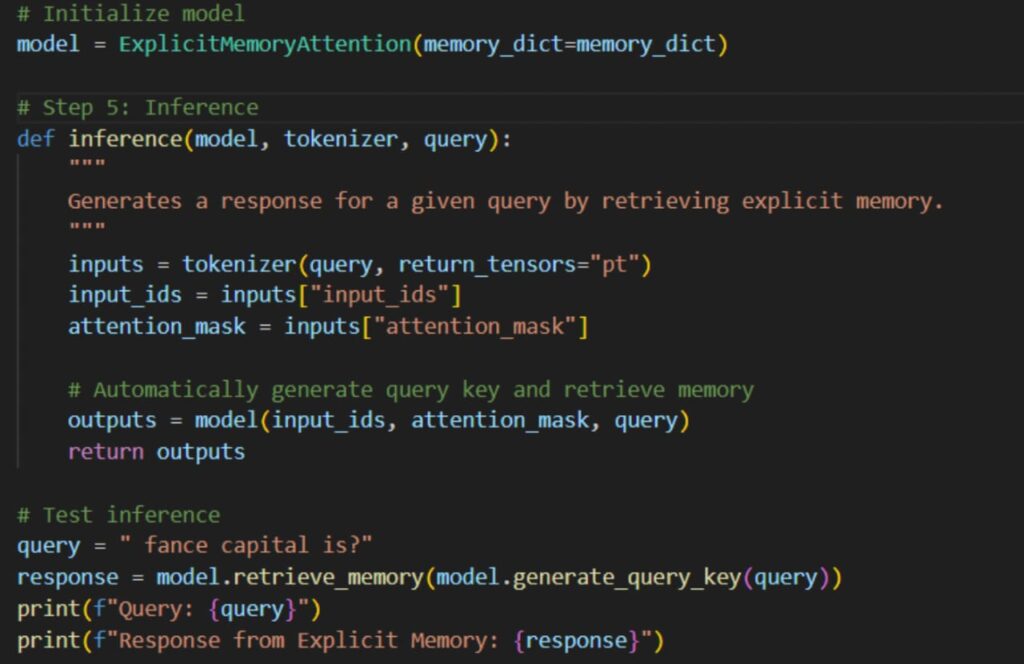
7. Initialization and testing the model
Advantages of Using Explicit Memory :
Decreased Model Size and Training Expenses – By transferring certain knowledge to external explicit memory, the model avoids the necessity of embedding all information within its parameters (implicit memory).
Effective Knowledge Preservation – Explicit memory serves as a more cost-effective method for storing knowledge in comparison to model parameters.
Quicker and More Effective Inference – Explicit memory can be accessed and handled more efficiently than retrieving raw text in systems such as retrieval-augmented generation (RAG). Precomputed key-value pairs enable direct incorporation into the Transformer self-attention layers without the need for distinct encoding processes.
Improved Scalability – The model’s dimensions stay constant while the dedicated memory bank expands as required. New information can be incorporated or revised in the memory bank without the need to retrain the model.
Enhanced Long-Context Handling – Externalized memory can be saved and accessed as required, circumventing the constraints of Transformer designs. This enables LLMs to handle extensive texts or substantial datasets effectively.
Factuality and Diminished Hallucination – As explicit memory organizes knowledge in an understandable format (accessible key-value pairs), it lowers the chances of hallucinations relative to depending only on implicit memory.
Reduced GPU Memory Needs – Explicit memory reduces the requirement for GPU memory while inferring. Only pertinent key-value pairs are loaded into memory, rather than necessitating the entire model to retain all information. This enhances the practicality of implementing LLMs on compact hardware devices.
Disadvantages of Using Explicit Memory :
Retrieval Delay – Because explicit memory is dependent on external storage (such a disk or RAM), retrieval can be delayed, especially if the memory is kept off-site or on slower storage systems. Compared to models that just rely on internal parameters, this may lead to slower inference.
Enhanced Complexity – By adding explicit memory, the model gains additional components such as memory encoding, storage, retrieval, and integration into the self-attention layers. These components increase the complexity of implementation and maintenance.
Risk of Information Exposure – Private or proprietary information could be exposed by unprotected external memory banks. Memory becomes a potential target for security breaches when it contains private or sensitive data.
Conclusion :
Employing Explicit Memory for language modeling demonstrates notable advancements in lowering the cost and complexity associated with training and inferencing large language models. It provides a more effective, scalable approach that preserves high performance and accuracy by transferring certain knowledge into explicit memories. This novel method tackles the challenges of computational expenses in language modeling, creating opportunities for more sustainable and accessible AI technologies.