
What is Federated Learning?
Federated learning is a machine learning technique that allows multiple devices or serves to collaboratively train a model without sharing their raw data. Instead of sending data to a central server.
Here are the steps how federated learning done:
- Each device trains the model locally on its own data,
- Sends only the model updates (like weights or gradients) to a central server,
- The central server aggregates these updates to improve the global model,
- Then send the updated global model back to all participants for the next training model.
But here’s the problem:
What if the data on each device is very different?
For Example - one device has photos of cats taken indoors, while another has outdoor cat photos. If the model isn't flexible enough, it might fail when faced with new, unseen data.
This is where Federated Domain Generalization comes into the picture (FedDG).
Federated Domain Generalization (FedDG) combines two concepts in machine learning:
- Federated Learning (FD) - training models across decentralized clients without sharing their raw data.
- Domain Generalization (DG) - training a model that performs well on unseen domains (i.e., data distribution not seen during training).
FedDG = Federated Learning + Adapting to new Situations
FedDG makes sure the AI doesn’t just memorize each person’s data but learns patterns that work everywhere, even in unseen environments.
Example:
- You train on indoor dog pics.
- Your friend trains on cartoon dog pics.
- Another friend trains on blurry dog pics.
Instead of making an AI that only works well on one type, FedDG ensures the final model can recognize dogs no matter how they look, even if it’s a style it has never seen before!
Why Is This a Challenge?
- No Central Data Pool: Since data stays private, the AI can’t see everything at once.
- Different Styles = Different "Domains": Each person’s data is like a different "domain" (e.g., sketches, real photos, paintings).
- Goal: Generalize well without ever seeing the test data during training.
Solution:-
A new method called TRIP (Token-level pRompt mIxture with Parameter-free routing) makes this even smarter. Instead of using a one-size-fits-all approach, TRIP customizes how the AI processes different parts of an image, improving accuracy while keeping communication costs low.
The TRIP method makes FedDG even smarter by:
- Breaking images into parts (e.g., fur, background) and assigning different "experts" to handle each.
- Avoiding extra communication costs (no heavy back-and-forth updates).
- Balancing personal + global knowledge so the AI doesn’t overfit one person’s data.
Experts make TRIP smarter, faster, and more private than standard models!
New Challenge: One Prompt Doesn’t Fit All
Many AI models today use prompt learning, where small pieces of data (called "prompts") guide the model’s behavior. In federated learning, previous methods used a single global prompt for all devices. But since data varies across devices, this approach struggles to adapt to different styles (like sketches vs. real photos).
Some newer methods were tried using multiple prompts (experts) and assigning different images to different experts. But they had two big flaws:
- Coarse Assignments: They assigned entire images to experts, ignoring that different parts of an image (like background vs. object) might need different experts.
- High Communication Costs: They needed extra trainable components (routers) to decide which expert to use, increasing the data sent between devices and the central server.
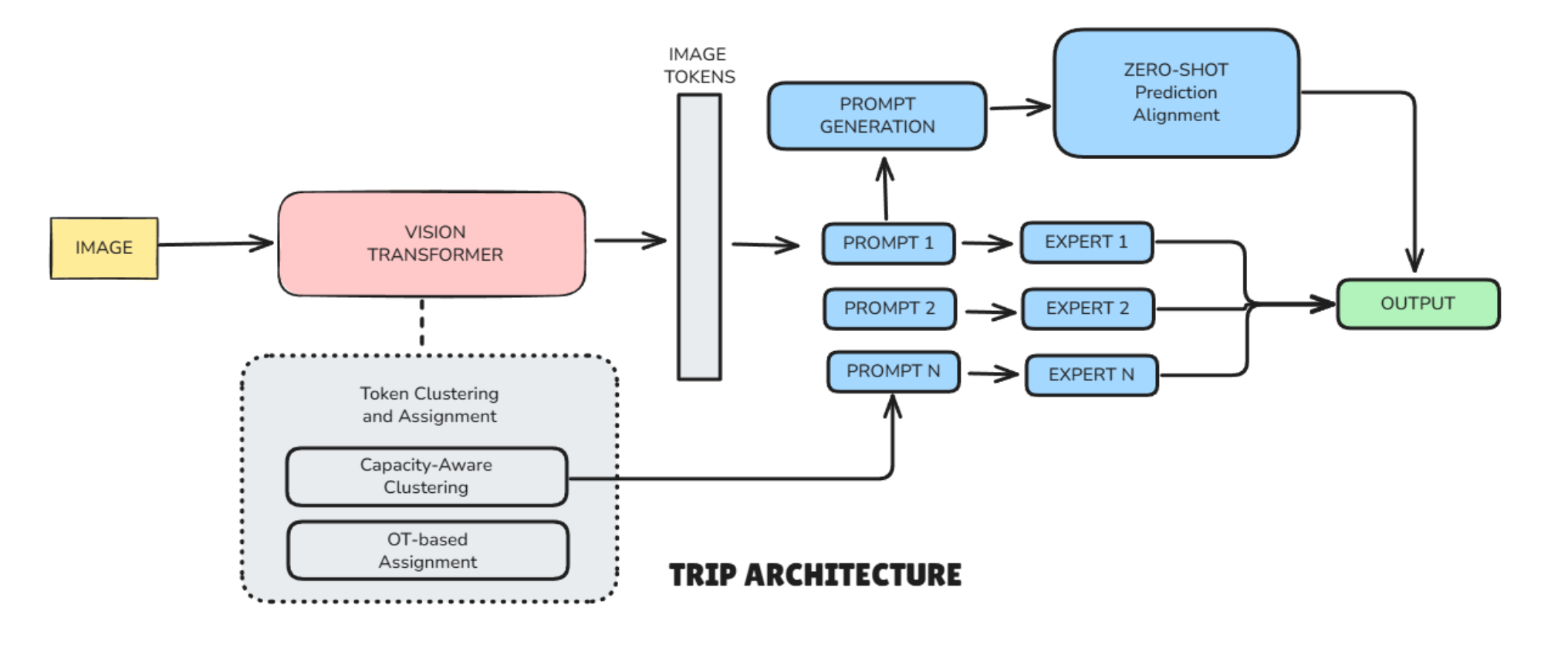
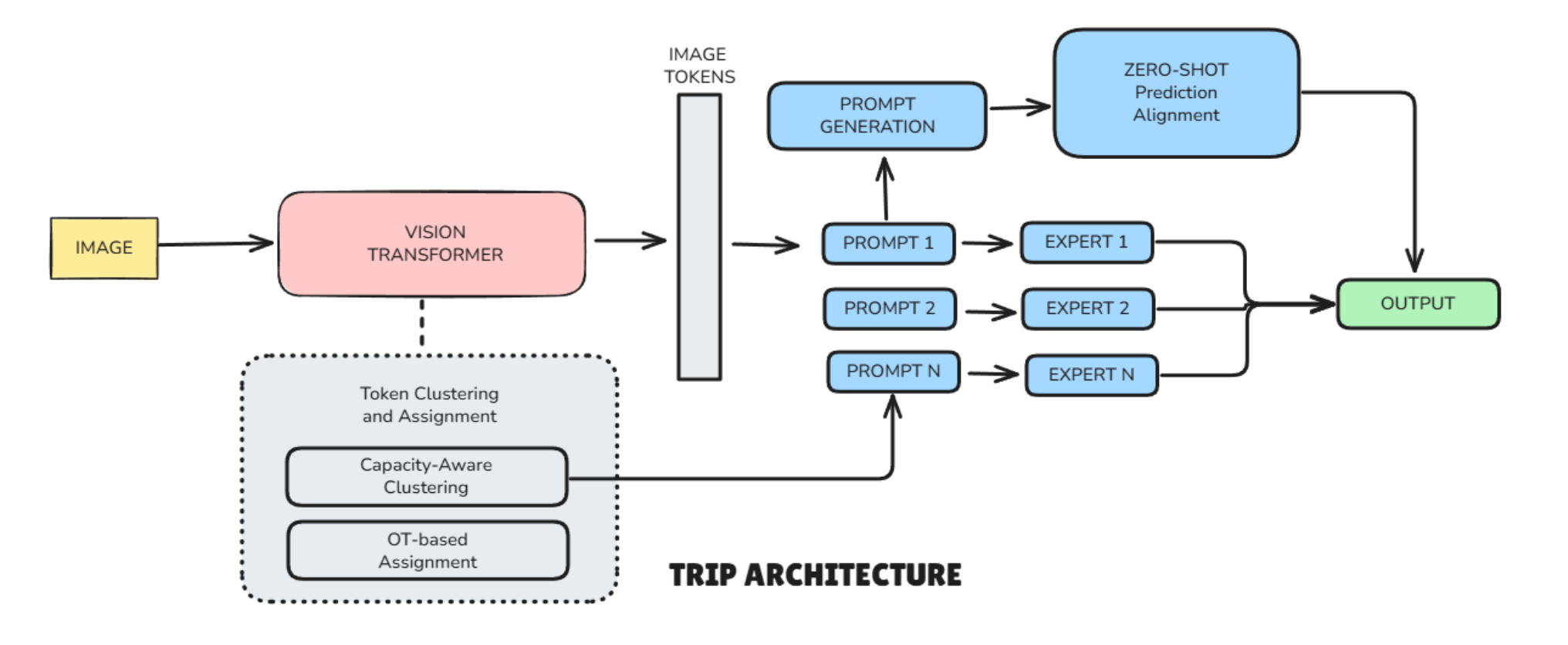
TRIP Architecture
How TRIP Solves These Problems:
TRIP introduces a smarter way to assign prompts—token-level routing.
Here’s how it works in simple terms:
- Breaking Images into Tokens: Instead of treating the whole image as one piece, TRIP splits it into smaller parts (tokens). For example, a cat photo might be divided into patches representing the cat’s face, body, and background.
- Smart Grouping with Clustering: TRIP groups with similar tokens together (like all cat-face patches) using a technique called capacity-aware clustering. This ensures that no single expert gets overloaded with too many tokens.
- Assigning Experts Without Extra Training: Instead of using a trainable router (which adds communication costs), TRIP uses Optimal Transport (OT), a math trick that efficiently matches token groups to the best expert. To keep things stable, it uses fixed "keys" that don’t change during training.
- Combining Experts for the Final Decision : Each expert specializes in certain features (like textures or shapes). TRIP combines their knowledge based on how many tokens were assigned to each, creating a custom prompt for each image.
- Avoiding Bias with Zero-Shot Learning: Since each device trains on its own data, prompts might become too specialized. TRIP fixes this by aligning local predictions with CLIP’s zero-shot guesses (a pre-trained AI’s unbiased estimates). This keeps the model balanced between personalization and generalization.
Why TRIP Stands Out
- Better Accuracy: By focusing on fine-grained details (not just whole images), TRIP captures more useful patterns.
- Low Communication Costs: No extra trainable routers mean less data is sent between devices and servers.
- Balanced Learning: The zero-shot alignment prevents overfitting to any single device’s data.
Key Improvements of TRIP Over CLIP
1. No One-Size-Fits-All Prompts:
- CLIP: Uses the same prompt ("a photo of a dog") for all dog images.
- TRIP: Uses different prompts for different parts of the image (e.g., one expert for fur, another for shadows).
2. Works in Federated Learning:
- CLIP can’t handle data spread across devices privately.
- TRIP trains locally on each device and only shares small prompt updates.
3. Better for Diverse Data:
- If one device has cartoon dogs and another has real photos, TRIP adapts prompts without overfitting.
4. No Extra Data Needed:
- CLIP relies on its pre-training.
- TRIP fine-tunes CLIP efficiently without needing new centralized data.
Real-World Example
- CLIP: Like a chef who only knows one recipe ("a photo of a [CLASS]").
- TRIP: Like a team of chefs, each specializing in a different ingredient (fur, eyes, background), working together without sharing their secret recipes.
Results
Tests on four datasets (PACS, Office-Home, VLCS, and DomainNet) showed TRIP beating other methods while using only 1,000 parameters per communication round, far less than competitors. Even its lightweight version (TRIP-Lite) performed well with minimal resources.
Conclusion
TRIP is a big step forward in federated learning. By smartly assigning different parts of an image to specialized experts without extra communication costs, it makes AI models more accurate and adaptable. This could lead to better privacy-preserving AI in healthcare, smart devices, and more.


