In the rapidly evolving landscape of Artificial Intelligence and Machine Learning (AIML), rapid model training is crucial. As models become more complex, the need for tools that streamline training processes has grown. Hugging Face’s Accelerate library emerges as a powerful solution for AIML engineers providing a user-friendly interface to manage distributed training mixed precision, and hardware utilization. This blog will delve into capabilities of acceleration, how to get started, and best practices for leveraging its features.
What is Accelerate?
Accelerate is a lightweight library created that simplifies the training of PyTorch models across various hardware configurations. It abstracts away the complexities of training pipelines enabling users to focus on developing their models. The library allows for seamless transitions between different training setups whether on a single GPU multiple GPU, or even TPUs.
Key Features of Accelerate
- Ease of use: Accelerate is designed to minimize the amount of code required for distributed training, making it accessible even for those new to the domain.
- Distributed Training: With built-in support for distributed training, Accelerate automatically handles device placement and synchronization, allowing users to their effortlessly.
- Mixed Precision Training: The library supports distributed training. Accelerate automatically handles device placement and synchronization, allowing users to scale their training effortlessly.
- Flexibility: Accelerate integrates seamlessly with existing PyTorch codebases, allowing engineers to adopt it without needing to rewrite their training scripts entirely.
- Configuration: Users can easily configure different training settings (like precision and device) through a straightforward command line interface.
Getting started with Accelerate:
Step 1: Import libraries

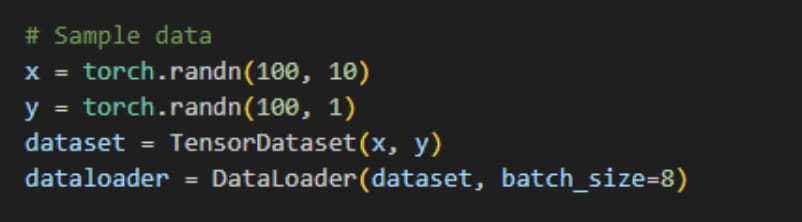
Step 2: Declare dataset
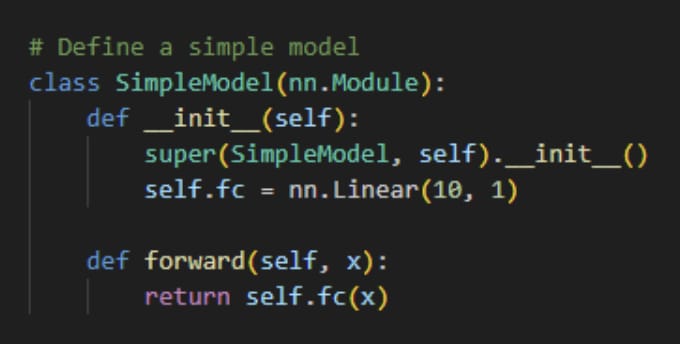
Step 3: Define a model
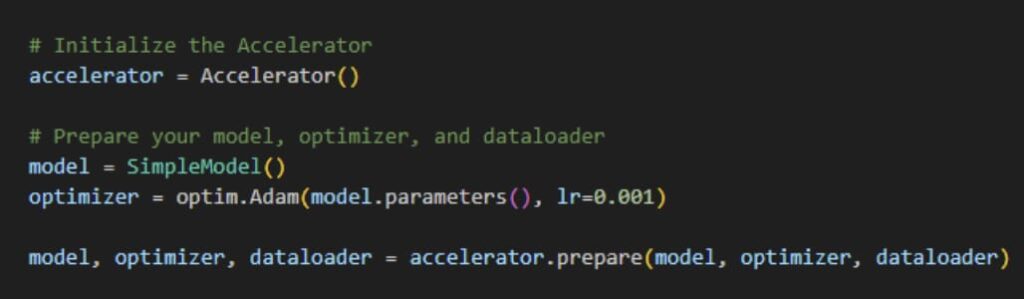
Step 4: Initialize Accelerate
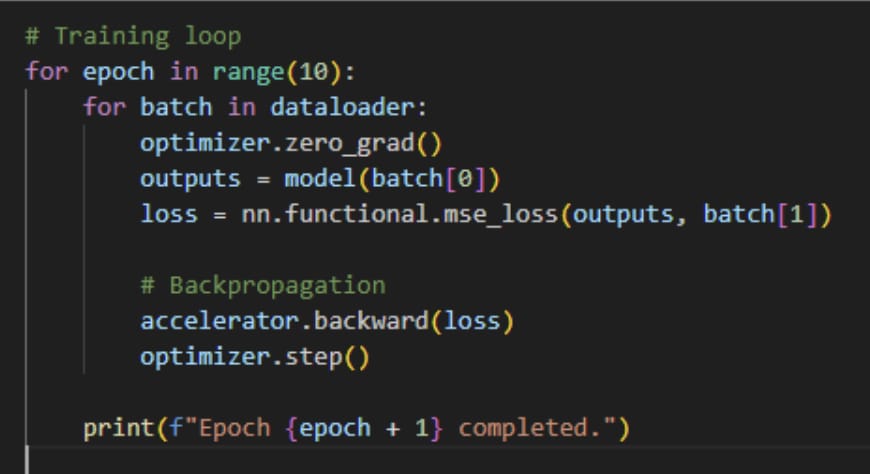
Step 5: Training loop
Advantages of Using Accelerate
Simplifies Distributed Training: Accelerate handles all the complexities of distributed training making it easy for users to scale their models without deep technical knowledge.
Performance Optimization: The library’s support for mixed precision can lead to faster training times and reduced memory usage, particularly beneficial for large models.
Rapid Prototyping: Engineers can quickly iterate on model design and configuration due to the minimal setup required for training pipelines.
Flexibility: It works seamlessly with existing PyTorch code allowing developers to integrate it into their projects easily without extensive modifications.
Comprehensive Documentation: The library is well documented, providing users with clear guidelines, examples and best practices.
Disadvantages of Using accelerate
Limited to PyTorch : Accelerate is specifically designed for PyTorch, so users of other deep leaning frameworks may not benefit from its features.
Learning curve: While it simplifies many tasks, users still need to understand the underlying concepts of distributed training and mixed precision to use the library effectively.
Debugging Complexity: When training in distributed setting debugging can become more complex making it challenging to identify the source of errors.
Dependency Management: Users must ensure that their environment is correctly set up for the libraries and tools that Accelerate relies on, which may involve additional configuration.
Resource Intensive: Utilizing multiple GPUs or TPUs can be resource-intensive requiring careful management of resources and potentially leading to their highest cost for cloud-based solutions.
Best Practices for Using Accelerate:
Monitor GPU Usage: When training on GPUs monitor their utilization using tools like nvidia-smi to ensure that you are effectively using available resources.
Experiment with Mixed Precision: Enabling mixed precision can yield performance benefits, especially when training large models. Ensure your hardware supports it.
Checkpoints: Save your model checkpoints at regular intervals to avoid losing progress during training, especially for longer runs.
Debugging: If you encounter issues, try running your script in a single-GPU configuration first to isolate problems before scaling up to multi-GPU or TPU setups.
Conclusion :
Hugging face’s Accelerate library is an asset for AIML engineers looking to optimize and simplify the training of deep learning models. It’s easy to use, supports mixed precision and distributed training, and seamless integration with PyTorch makes it an ideal choice for both beginners and experienced practitioners.
By leveraging Accelerate, you can focus more on the intricacies of model design and experimentation while the library takes care of the heavy lifting associated with training pipelines. Whether you’re working on a small project or scaling up large data sets, Accelerate can enhance your workflow and productivity.