The world is buzzing with generative AI models that can create stunning images from text, write human-like poetry, or synthesize realistic audio. While these powerful models often run on massive server farms, there’s a growing hunger to bring this magic directly to our personal devices: our smartphones, tablets, and laptops. Why? For better privacy, quicker responses, offline capabilities, and lower server costs.
But there’s a catch. These new-age AI models are huge, often 10 to 100 times larger in terms of parameters than what we’re used to seeing on our devices. Squeezing them onto resource-constrained gadgets and making them run fast is a monumental engineering challenge.
Enter ML Drift, a groundbreaking framework designed to scale up on-device GPU inference for these large generative models. It’s like giving your device’s graphics processing unit (GPU) a supercharger specifically for AI.
What is ML Drift?
At its core, Machine Learning Drift is an optimized software framework that extends the capabilities of existing GPU-accelerated inference engines. It’s specifically built to tackle the deployment challenges of large generative models on a wide array of GPUs – from the ones in your Android phone (Qualcomm Adreno, Arm Mali) to your laptop (Intel, NVIDIA) and even Apple Silicon.
The goal is simple but ambitious: to enable the execution of significantly more complex AI models on devices we use every day, achieving performance improvements that are an order of magnitude better than existing open-source solutions.
How Does ML Drift Work its Magic?
ML Drift isn’t just one trick; it’s a suite of sophisticated optimizations working in concert. Here are some of the key ingredients:
1.Tensor Virtualization: Flexible Data Handling:
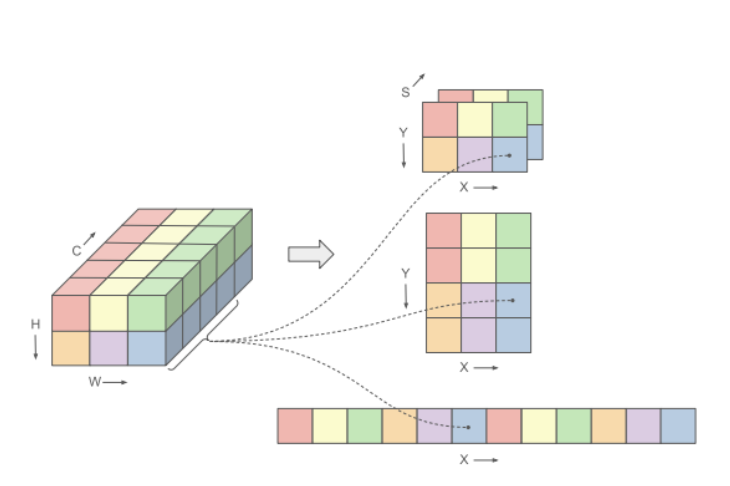
Think of how your computer uses virtual memory to manage more data than it has physical RAM. Tensor Virtualization does something similar for AI data (tensors) on the GPU. It decouples the logical way AI models think about data (e.g., a 5-dimensional array) from how that data is physically stored on the GPU (e.g., as a 2D texture, a 1D buffer, or even spread across multiple GPU memory objects).
This flexibility allows ML Drift to choose the most efficient physical storage format for different types of data and GPU operations, leading to better performance.
Also Read Our Blog: Language Modeling with Explicit Memory
2. Coordinate Translation: The Smart GPS for Data
To make Tensor Virtualization work seamlessly, Machine Learning Drift uses “coordinate translation.” During an initial setup phase, it figures out how to translate a request for a specific data point (logical coordinates) into the actual location on the GPU’s physical memory.
This mapping is done upfront, so there’s no performance hit when the AI model is actually running. It lets the different parts of the AI model access data flexibly without getting bogged down in complex memory management.
3. Device Specialization: Tailored for Your GPU
Not all GPUs are created equal. ML Drift intelligently adapts its operations based on the specific GPU it’s running on.
Here’s how it works:
- Adaptive Kernel Selection: It picks the fastest “mini-programs” (kernels) for specific tasks from a library of options, based on the GPU’s capabilities.
- Vendor-Specific Tricks: It leverages special hardware features or extensions provided by GPU manufacturers (like specialized matrix multiplication instructions on Arm GPUs).
- Code Transformation: It translates a high-level description of an AI operation into the specific shader language (like OpenCL, Metal, or WebGPU) that the target GPU understands best.
- Optimal Weight Storage: Model weights (the learned parameters) are pre-processed and stored in the most efficient layout for the GPU.
This custom-tailoring squeezes out maximum performance from each unique GPU architecture.
4. Smarter Memory Management: No Wasted Space
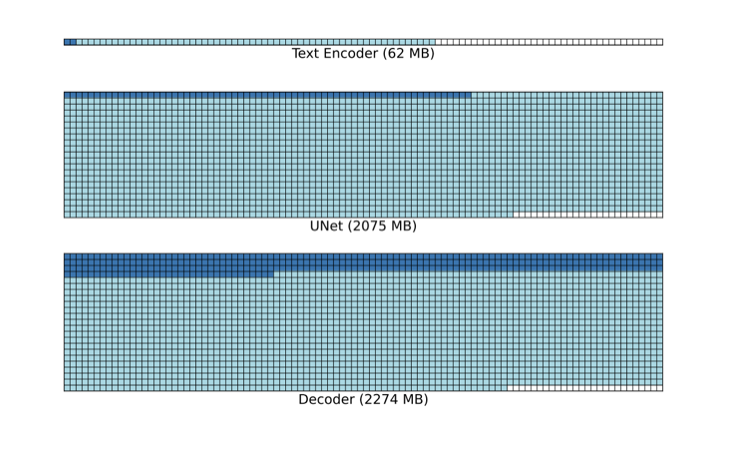
5. Operator Fusion: Doing More with Less
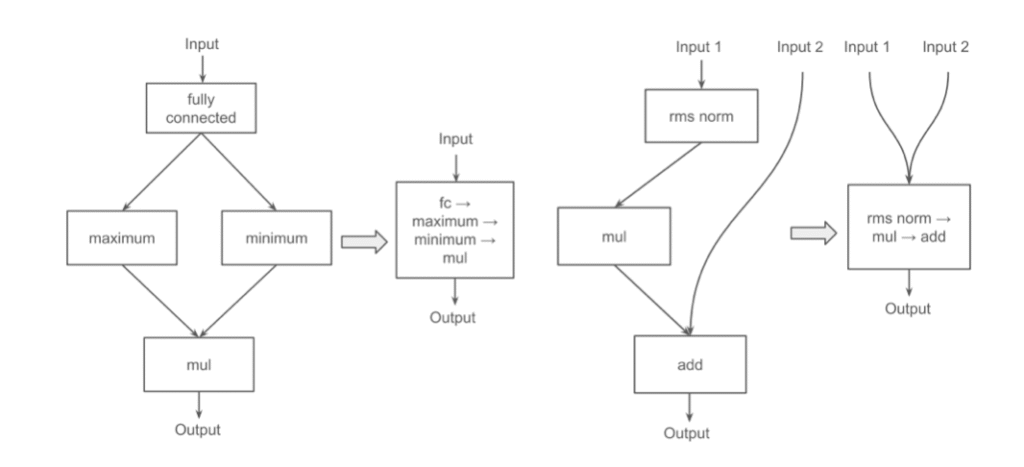
Instead of running many small, separate operations (each with its own overhead), ML Drift often fuses them into a single, larger, more efficient kernel. This reduces the overhead of launching kernels and transferring data between operations, speeding things up.
6. Stage-Aware LLM Optimizations: Different Strokes for Different Folks
For Large Language Models (LLMs), ML Drift distinguishes between the “prefill” stage (processing the initial prompt, which is compute-intensive) and the “decode” stage (generating new tokens one by one, which is memory-bound). It applies different optimization strategies to each.
This tailored approach maximizes performance for both distinct phases of LLM inference.
Also Read Our Blog: B2B User Registration in Sap Commerce
7. GPU-Optimized KV Cache Layout:
In LLMs, the “KV cache” stores information about what’s already been generated to help produce the next token. ML Drift stores this cache in a highly optimized layout that works well with the GPU kernels used for matrix multiplication.
Efficient KV cache handling is crucial for fast token generation in LLMs.
"Show Me the Numbers!" (Performance Highlights)
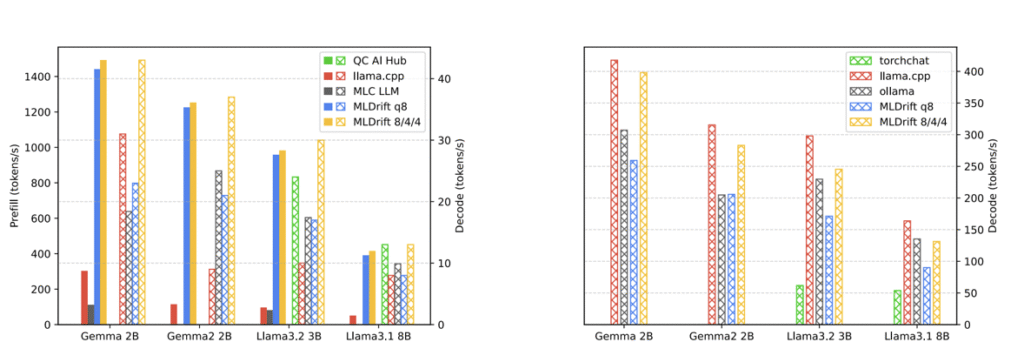
ML Drift isn’t just theoretical; it delivers real-world speedups. Here’s a snapshot from the paper’s abstract table:
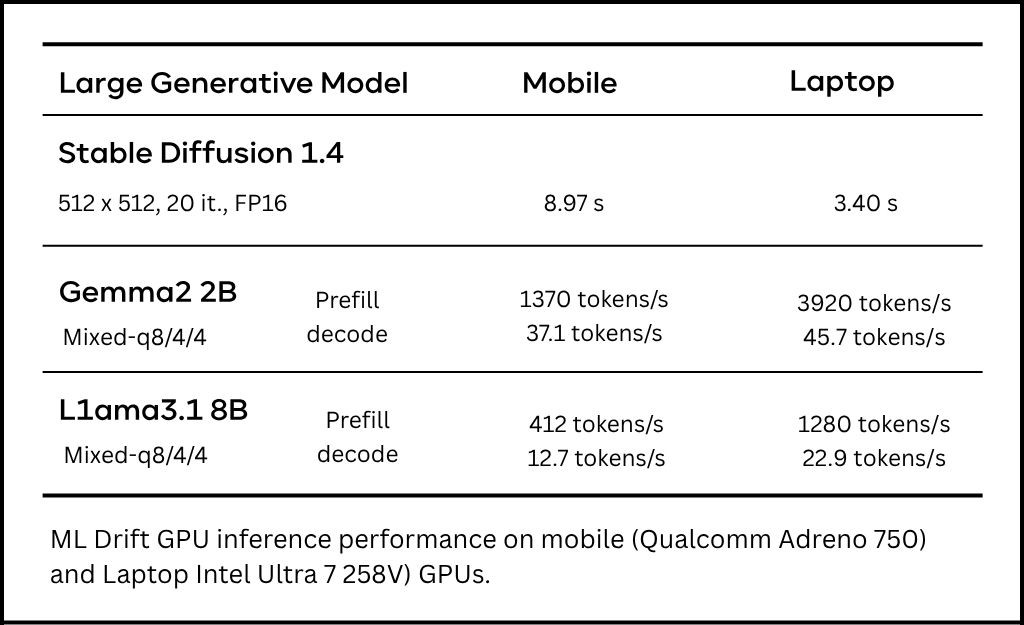
For instance, on a Samsung S23 Ultra (Adreno 740 GPU), ML Drift ran Stable Diffusion 1.4 image generation in under 11 seconds, and under 9 seconds on an S24 (Adreno 750). For LLMs on mobile, ML Drift showed 5x to 11x speedups in token prefill compared to other open-source solutions.
Why is ML Drift a Big Deal?
- It allows models that are 10-100 times larger than previously feasible to run on your local device.
- It offers an order-of-magnitude performance boost over existing open-source GPU inference engines.
- It’s designed to work across a wide spectrum of GPUs found in mobile, desktop, and Apple devices.
- Faster, more capable AI on your device means more responsive apps, better privacy, and the ability to use advanced AI features even when offline.
What’s Next for ML Drift?
The journey doesn’t stop here. The team behind ML Drift plans to:
- Incorporate more advanced quantization techniques (making models even smaller and faster).
- Leverage sparsity (many AI models have lots of zeros that can be skipped).
- Explore more specialized hardware instructions as they become available on new GPUs.
- Extend support to newer diffusion models and transformer architectures.
- Improve interoperability with other processors on the device (like CPUs and NPUs) for even more efficient hybrid execution.
Conclusion
ML Drift represents a significant leap forward in making large-scale generative AI practical for everyday devices. By cleverly decoupling logical data from physical storage, specializing operations for diverse hardware, and meticulously managing memory, it pushes the boundaries of what’s possible on resource-constrained platforms. This technology is a key enabler for a future where powerful, personalized AI is not just in the cloud, but right in our pockets and on our desks.